Rows: 169
Columns: 17
$ country_name <chr> "Mexico", "Suriname", "Sweden", "Switzerland"…
$ country_text_id <chr> "MEX", "SUR", "SWE", "CHE", "GHA", "ZAF", "JP…
$ year <dbl> 2020, 2020, 2020, 2020, 2020, 2020, 2020, 202…
$ region <fct> Latin America and the Caribbean, Latin Americ…
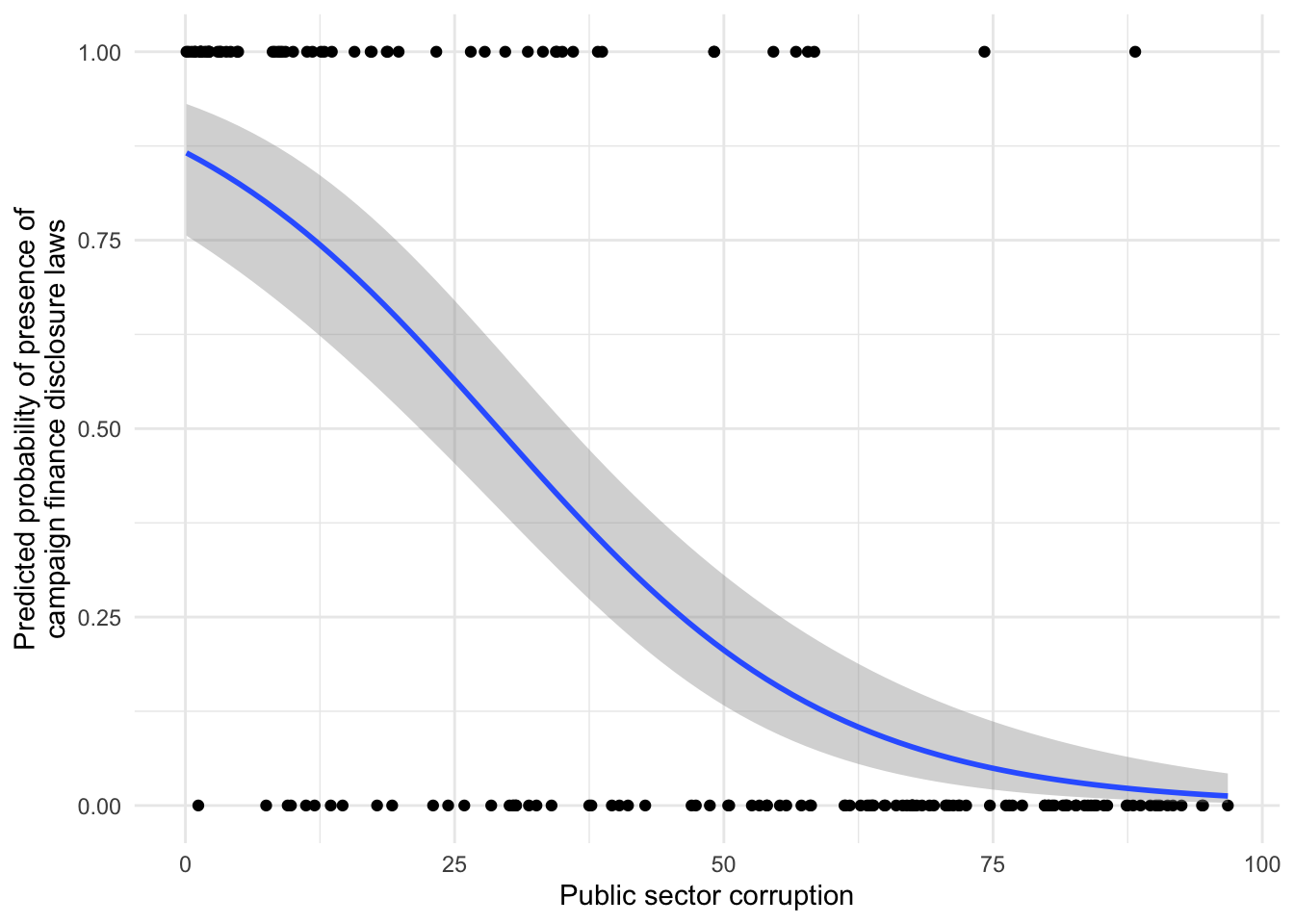
$ disclose_donations_ord <dbl> 3, 1, 3, 0, 2, 2, 3, 2, 2, 2, 2, 0, 3, 3, 4, …
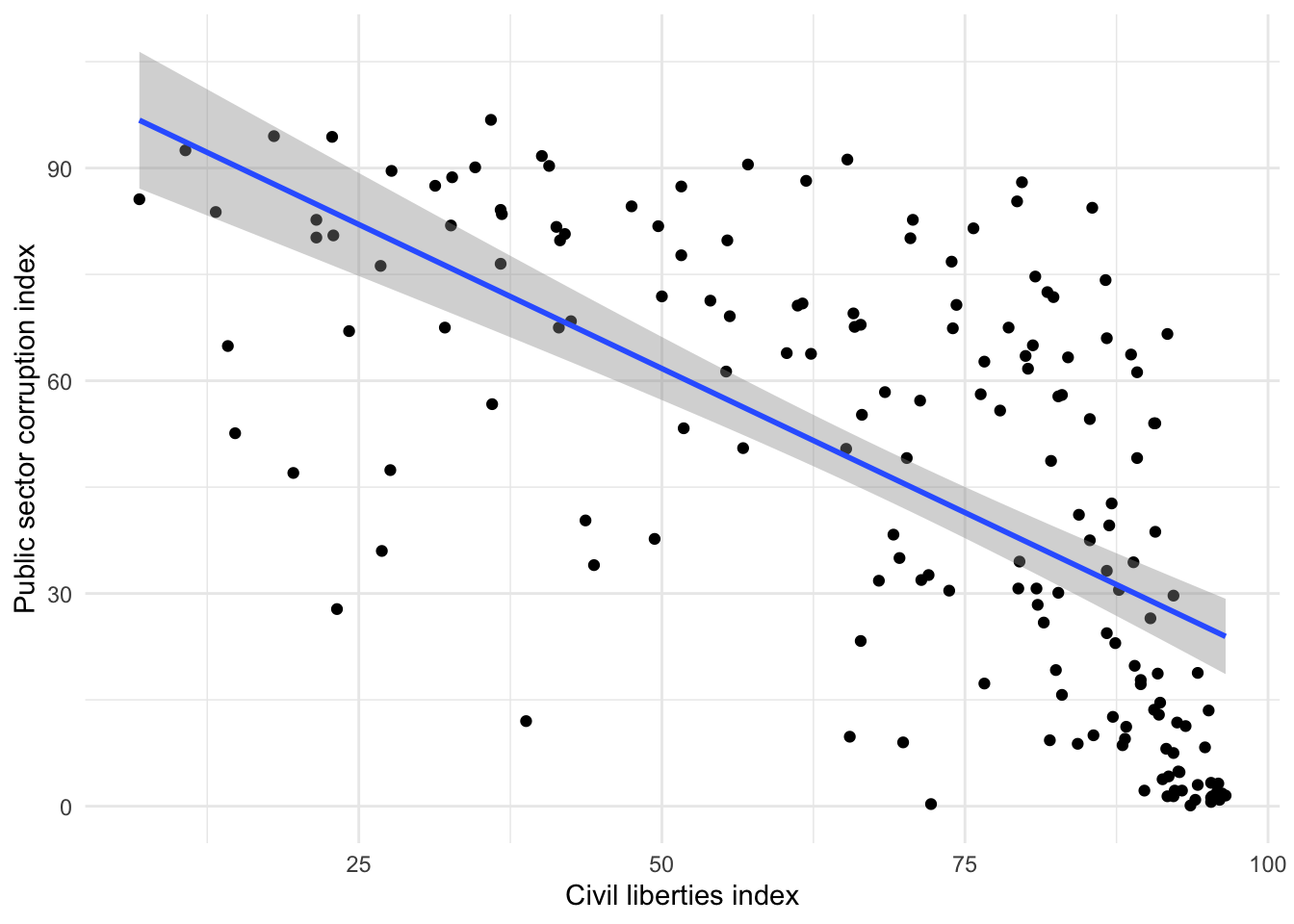
$ public_sector_corruption <dbl> 49.1, 24.4, 1.5, 1.2, 66.6, 58.0, 3.8, 37.7, …
$ polyarchy <dbl> 65.2, 75.4, 90.1, 90.1, 72.2, 71.4, 83.5, 42.…
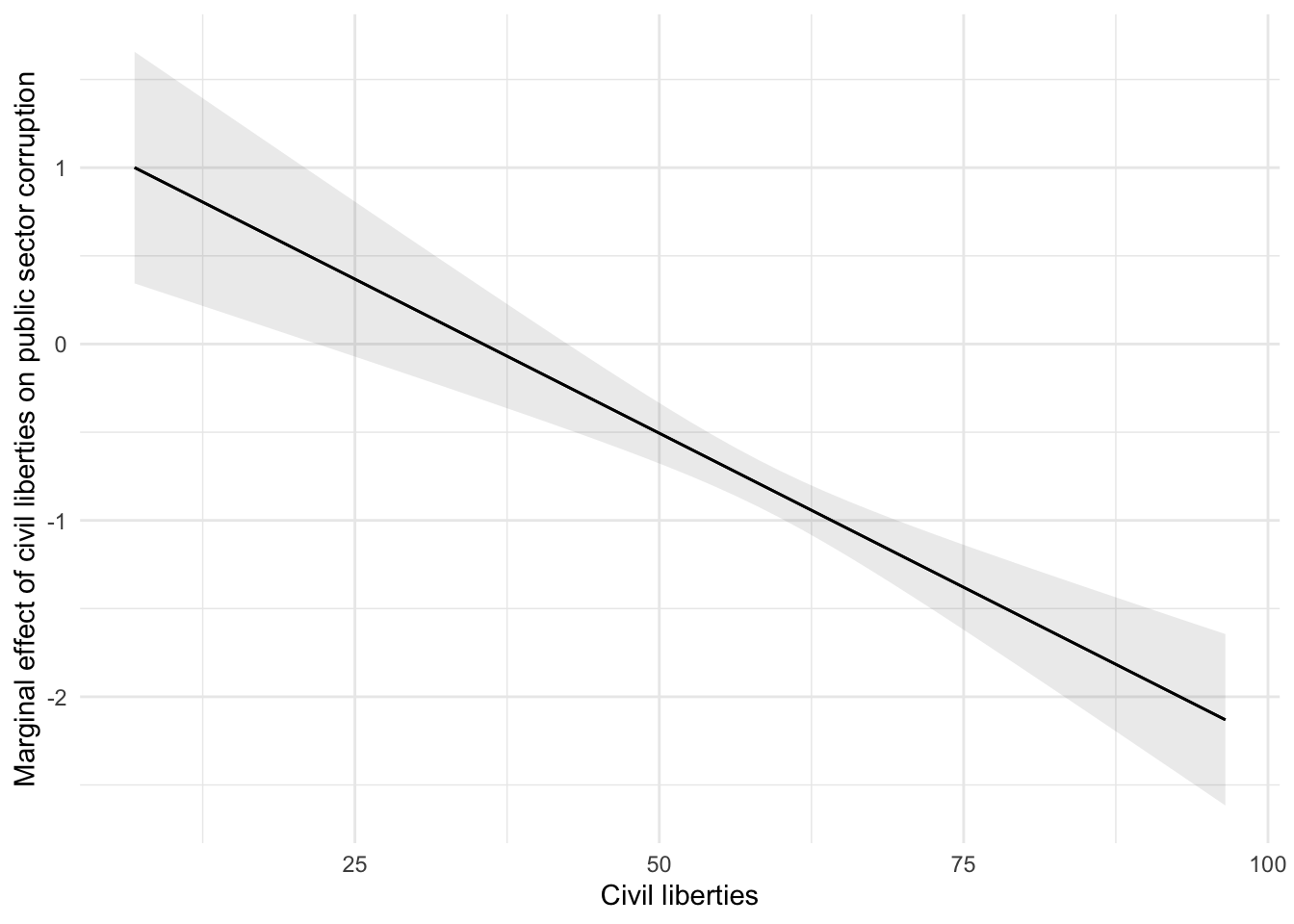
$ civil_liberties <dbl> 70.2, 86.7, 96.5, 95.3, 91.7, 83.0, 91.3, 49.…
$ disclose_donations <lgl> TRUE, FALSE, TRUE, FALSE, FALSE, FALSE, TRUE,…
$ iso2c <chr> "MX", "SR", "SE", "CH", "GH", "ZA", "JP", "MM…
$ population <dbl> 125998302, 607065, 10353442, 8638167, 3218040…
$ gdp_percapita <dbl> 9273.811, 7275.365, 51952.673, 84637.013, 195…
$ capital <chr> "Mexico City", "Paramaribo", "Stockholm", "Be…
$ longitude <chr> "-99.1276", "-55.1679", "18.0645", "7.44821",…
$ latitude <chr> "19.427", "5.8232", "59.3327", "46.948", "5.5…
$ income <chr> "Upper middle income", "Upper middle income",…
$ log_gdp_percapita <dbl> 9.134950, 8.892249, 10.858088, 11.346127, 7.5…