library(tidyverse)
library(viridis)
library(scales)
options(scipen = 999) # avoid printing in scientific notationAdjusting scales for World Bank indicators
Suggested answers
Application exercise
Answers
Important
These are suggested answers. This document should be used as reference only, it’s not designed to be an exhaustive key.
Data: World economic measures
The World Bank publishes a rich and detailed set of socioeconomic indicators spanning several decades and dozens of topics. Here we focus on a few key indicators for the year 2021.
gdp_per_cap- GDP per capita (current USD)pop- Total populationlife_exp- Life expectancy at birth, total (years)female_labor_pct- Labor force, female (% of total labor force)income_level- Classification of economies based on national income levels
The data is stored in wb-indicators.rds. To import the data, use the read_rds() function.
world_bank <- read_rds("data/wb-indicators.rds")Part 1: Transforming axes
Is there a relationship between a country’s per capita GDP and life expectancy? Let’s explore this relationship using a scatterplot.
ggplot(data = world_bank, mapping = aes(x = gdp_per_cap, y = life_exp)) +
geom_point() +
labs(
title = "Countries with higher GDP tend to have higher life expectancy",
x = "GDP per capita (current USD)",
y = "Life expectancy at birth (years)"
)
Seems like there is an association, but the relationship is not linear. Let’s try a log transformation on the \(x\)-axis to see if that helps.
Your turn: Log-transform the \(x\)-axis by mutating the original column prior to graphing.
Note
By default, log() computes natural logarithms (base-\(e\)). To compute base-10 logarithms, use log10().
world_bank |>
mutate(gdp_per_cap = log10(gdp_per_cap)) |>
ggplot(mapping = aes(x = gdp_per_cap, y = life_exp)) +
geom_point() +
labs(
title = "Countries with higher GDP tend to have higher life expectancy",
x = "GDP per capita (current USD, log10 scale)",
y = "Life expectancy at birth"
)![]()
Your turn: Now log-transform the \(x\)-axis by using the original per capita GDP measure and an appropriate scale_x_*() function.
ggplot(data = world_bank, mapping = aes(x = gdp_per_cap, y = life_exp)) +
geom_point() +
scale_x_log10() +
labs(
title = "Countries with higher GDP tend to have higher life expectancy",
x = "GDP per capita (current USD) (log10 scale)",
y = "Life expectancy at birth"
)![]()
Your turn: Which is more interpretable, and why?
Log-transforming the column first results in a plot with non-sensical labels on the \(x\)-axis. People do not intuitively understand log scales – we have to exponentiate out of them to understand what they represent. This is occasionally the case with base-10 logarithmic transformations, but often we employ natural logarithms (or base-\(e\) transformations) to transform variables.
It’s better to use the scale_*_log10() function to transform the axis directly. This way, the labels are directly human-readable.
Part 2: Customize scales
Let’s consider the relationship between female labor participation and per capita GDP. We’ll use the income_level variable to color the points and provide context on the overall wealth of the countries.1
Step 1: Base plot
First, let’s generate a color-coded scatterplot with a single smoothing line.
ggplot(data = world_bank, mapping = aes(x = female_labor_pct, y = gdp_per_cap)) +
geom_point(mapping = aes(color = income_level)) +
geom_smooth(se = FALSE)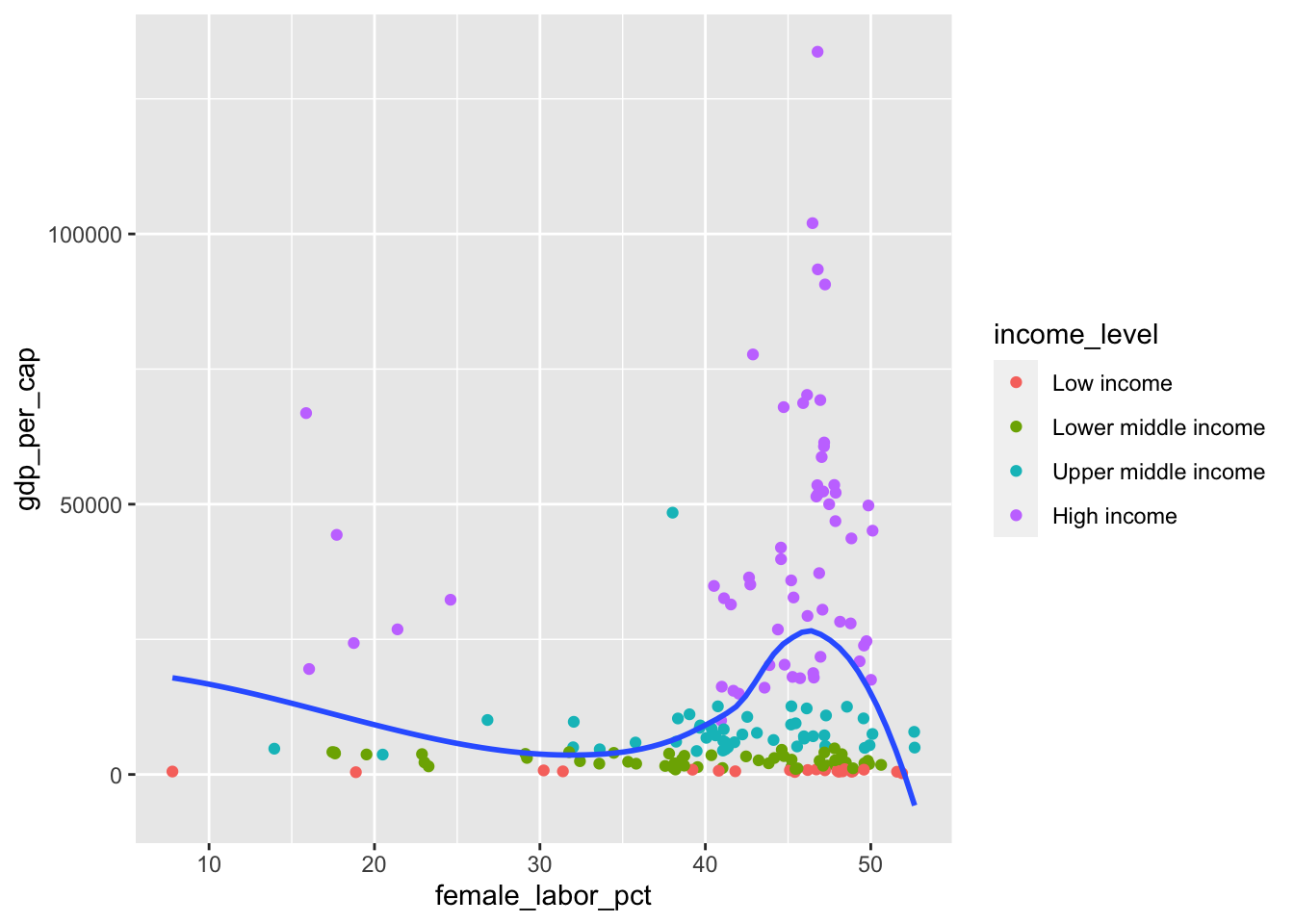
Step 2: Your turn
Now, let’s modify the scales to make the chart more readable. Log-transform the \(y\)-axis and format the labels so they are explicitly identified as percentages and currency.
ggplot(data = world_bank, mapping = aes(x = female_labor_pct, y = gdp_per_cap)) +
geom_point(mapping = aes(color = income_level)) +
geom_smooth(se = FALSE) +
scale_x_continuous(labels = label_percent(scale = 1)) +
scale_y_log10(labels = label_dollar())
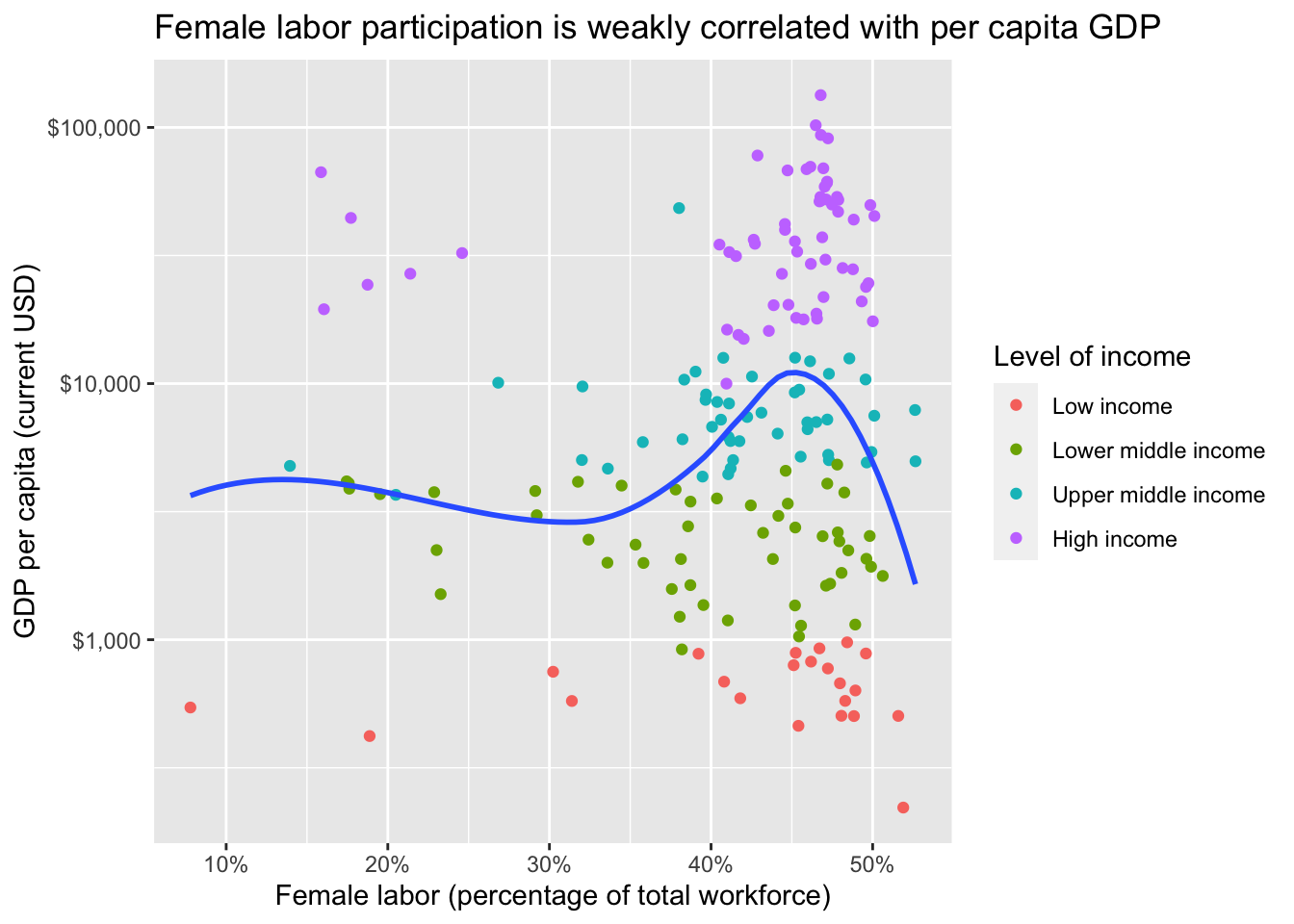
Step 3: Your turn
Add human-readable labels for the title, axes, and legend.
ggplot(data = world_bank, mapping = aes(x = female_labor_pct, y = gdp_per_cap)) +
geom_point(mapping = aes(color = income_level)) +
geom_smooth(se = FALSE) +
scale_x_continuous(labels = label_percent(scale = 1)) +
scale_y_log10(labels = label_dollar()) +
labs(
title = "Female labor participation is weakly correlated with per capita GDP",
x = "Female labor (percentage of total workforce)",
y = "GDP per capita (current USD)",
color = "Level of income"
)
Step 4: Your turn
Use the viridis color palette for income_level.
Tip
The bright yellow at the end of the palette is hard on the eyes. You can condense the hue at which the color map ends using the end argument to the appropriate scale_color_*() function.
ggplot(data = world_bank, mapping = aes(x = female_labor_pct, y = gdp_per_cap)) +
geom_point(mapping = aes(color = income_level)) +
geom_smooth(se = FALSE) +
scale_x_continuous(labels = label_percent(scale = 1)) +
scale_y_log10(labels = label_dollar()) +
scale_color_viridis_d(end = 0.8) +
labs(
title = "Female labor participation is weakly correlated with per capita GDP",
x = "Female labor (percentage of total workforce)",
y = "GDP per capita (current USD)",
color = "Level of income"
)
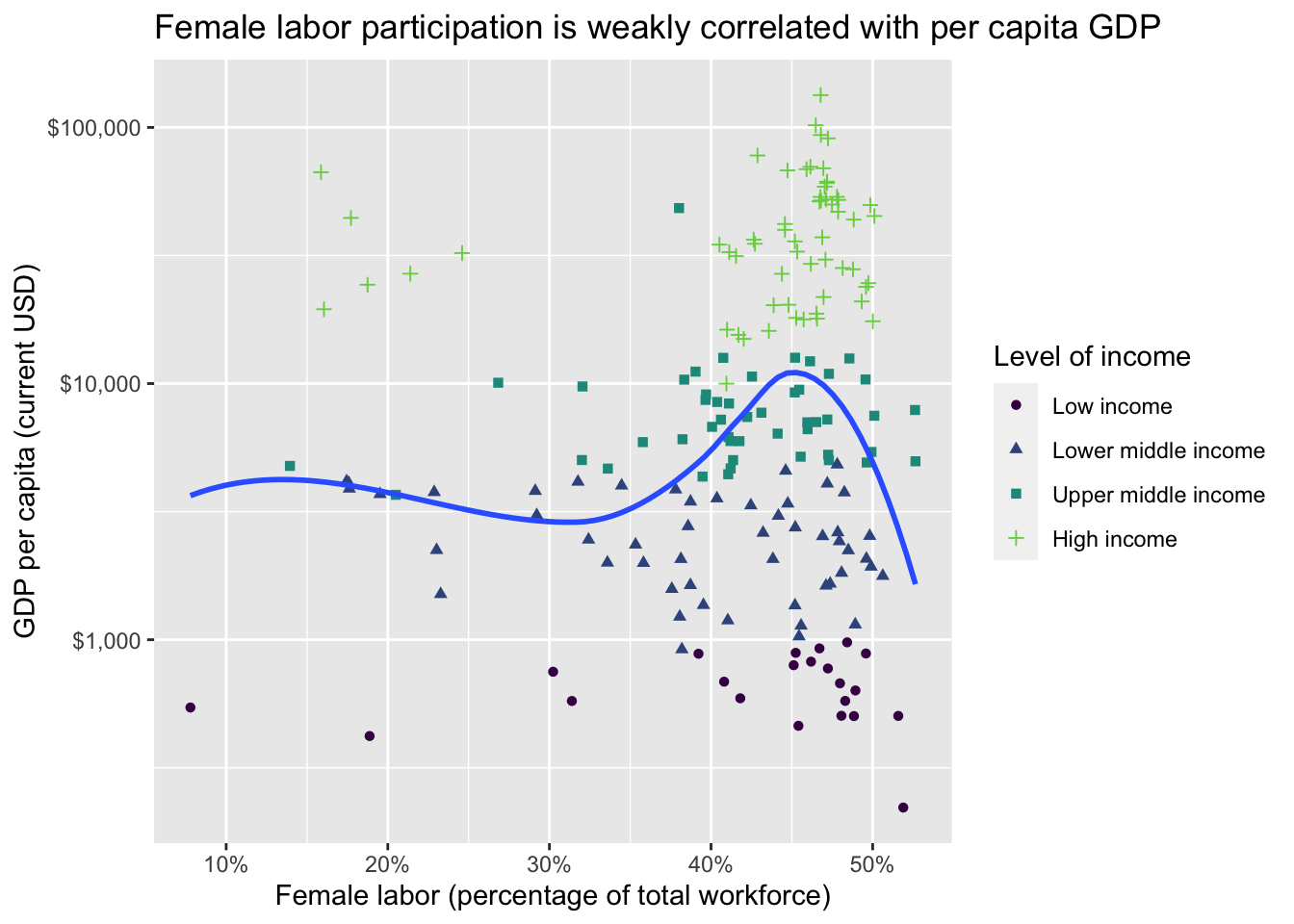
Step 5: Your turn
Double-encode the income_level variable by using both color and shape to represent the same variable. Condense the guides so you use a single legend.
ggplot(data = world_bank, mapping = aes(x = female_labor_pct, y = gdp_per_cap)) +
geom_point(mapping = aes(color = income_level, shape = income_level)) +
geom_smooth(se = FALSE) +
scale_x_continuous(labels = label_percent(scale = 1)) +
scale_y_log10(labels = label_dollar()) +
scale_color_viridis_d(end = 0.8) +
labs(
title = "Female labor participation is weakly correlated with per capita GDP",
x = "Female labor (percentage of total workforce)",
y = "GDP per capita (current USD)",
color = "Level of income",
shape = "Level of income"
)
Step 6: Your turn
It’s annoying that the order of the values in the legend are opposite from how the income levels are ordered in the chart. Reverse the order of the values in the legend so they correspond to the ordering on the \(y\)-axis.
ggplot(data = world_bank, mapping = aes(x = female_labor_pct, y = gdp_per_cap)) +
geom_point(mapping = aes(color = income_level, shape = income_level)) +
geom_smooth(se = FALSE) +
scale_x_continuous(labels = label_percent(scale = 1)) +
scale_y_log10(labels = label_dollar()) +
scale_color_viridis_d(end = 0.8, guide = guide_legend(rev = TRUE)) +
scale_shape_discrete(guide = guide_legend(rev = TRUE)) +
labs(
title = "Female labor participation is weakly correlated with per capita GDP",
x = "Female labor (percentage of total workforce)",
y = "GDP per capita (current USD)",
color = "Level of income",
shape = "Level of income"
)
Session information
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.3.2 (2023-10-31)
os macOS Ventura 13.5.2
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2024-02-08
pandoc 3.1.1 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
cli 3.6.2 2023-12-11 [1] CRAN (R 4.3.1)
colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)
digest 0.6.34 2024-01-11 [1] CRAN (R 4.3.1)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.3.1)
evaluate 0.23 2023-11-01 [1] CRAN (R 4.3.1)
fansi 1.0.6 2023-12-08 [1] CRAN (R 4.3.1)
farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)
fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)
forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)
generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)
ggplot2 * 3.4.4 2023-10-12 [1] CRAN (R 4.3.1)
glue 1.7.0 2024-01-09 [1] CRAN (R 4.3.1)
gridExtra 2.3 2017-09-09 [1] CRAN (R 4.3.0)
gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)
here 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)
htmltools 0.5.7 2023-11-03 [1] CRAN (R 4.3.1)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.3.1)
jsonlite 1.8.8 2023-12-04 [1] CRAN (R 4.3.1)
knitr 1.45 2023-10-30 [1] CRAN (R 4.3.1)
labeling 0.4.3 2023-08-29 [1] CRAN (R 4.3.0)
lattice 0.21-9 2023-10-01 [1] CRAN (R 4.3.2)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.3.1)
lubridate * 1.9.3 2023-09-27 [1] CRAN (R 4.3.1)
magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)
Matrix 1.6-1.1 2023-09-18 [1] CRAN (R 4.3.2)
mgcv 1.9-0 2023-07-11 [1] CRAN (R 4.3.2)
munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)
nlme 3.1-163 2023-08-09 [1] CRAN (R 4.3.2)
pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)
purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)
R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.3.1)
rlang 1.1.3 2024-01-10 [1] CRAN (R 4.3.1)
rmarkdown 2.25 2023-09-18 [1] CRAN (R 4.3.1)
rprojroot 2.0.4 2023-11-05 [1] CRAN (R 4.3.1)
rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)
scales * 1.2.1 2024-01-18 [1] Github (r-lib/scales@c8eb772)
sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)
stringi 1.8.3 2023-12-11 [1] CRAN (R 4.3.1)
stringr * 1.5.1 2023-11-14 [1] CRAN (R 4.3.1)
tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)
tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)
tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)
timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)
tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)
utf8 1.2.4 2023-10-22 [1] CRAN (R 4.3.1)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.3.1)
viridis * 0.6.4 2023-07-22 [1] CRAN (R 4.3.0)
viridisLite * 0.4.2 2023-05-02 [1] CRAN (R 4.3.0)
withr 2.5.2 2023-10-30 [1] CRAN (R 4.3.1)
xfun 0.41 2023-11-01 [1] CRAN (R 4.3.1)
yaml 2.3.8 2023-12-11 [1] CRAN (R 4.3.1)
[1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library
──────────────────────────────────────────────────────────────────────────────Footnotes
Note that the income level is based on the GNI per capita, which is strongly correlated with GDP per capita, but not exactly the same.↩︎