Explainable machine learning models
Lecture 25
May 4, 2023
Black-box model


Evaluation performance

Random forest feature importance
Code
explainer_glmnet <- explain_tidymodels(
model = glmnet_wf,
data = scorecard_train |> select(-debt),
y = scorecard_train$debt,
label = "penalized regression",
verbose = FALSE
)
explainer_rf <- explain_tidymodels(
model = rf_wf,
data = scorecard_train |> select(-debt),
y = scorecard_train$debt,
label = "random forest",
verbose = FALSE
)
explainer_kknn <- explain_tidymodels(
model = kknn_wf,
data = scorecard_train |> select(-debt),
y = scorecard_train$debt,
label = "k nearest neighbors",
verbose = FALSE
)
Number of observations permuted
model_parts(explainer_rf, N = 100) |>
plot() +
labs(
title = "N = 100",
subtitle = NULL
)
model_parts(explainer_rf, N = 200) |>
plot() +
labs(
title = "N = 200",
subtitle = NULL
)
model_parts(explainer_rf, N = NULL) |>
plot() +
labs(
title = "N = NULL",
subtitle = NULL
)Code

Code

Code

Compare all models
Code
# plot variable importance
# source: https://www.tmwr.org/explain.html#global-explanations
ggplot_imp <- function(...) {
obj <- list(...)
metric_name <- attr(obj[[1]], "loss_name")
metric_lab <- paste(
metric_name,
"after permutations\n(higher indicates more important)"
)
full_vip <- bind_rows(obj) |>
filter(variable != "_baseline_")
perm_vals <- full_vip |>
filter(variable == "_full_model_") |>
group_by(label) |>
summarise(dropout_loss = mean(dropout_loss))
p <- full_vip |>
filter(variable != "_full_model_") |>
mutate(variable = fct_reorder(variable, dropout_loss)) |>
ggplot(aes(dropout_loss, variable))
if (length(obj) > 1) {
p <- p +
facet_wrap(vars(label)) +
geom_vline(
data = perm_vals, aes(xintercept = dropout_loss, color = label),
size = 1.4, lty = 2, alpha = 0.7
) +
geom_boxplot(aes(color = label, fill = label), alpha = 0.2)
} else {
p <- p +
geom_vline(
data = perm_vals, aes(xintercept = dropout_loss),
size = 1.4, lty = 2, alpha = 0.7
) +
geom_boxplot(fill = "#91CBD765", alpha = 0.4)
}
p +
theme(legend.position = "none") +
labs(
x = metric_lab,
y = NULL, fill = NULL, color = NULL
)
}
vip_rf <- model_parts(explainer_rf, N = NULL)
vip_glmnet <- model_parts(explainer_glmnet, N = NULL)
vip_kknn <- model_parts(explainer_kknn, N = NULL)
ggplot_imp(vip_rf, vip_glmnet, vip_kknn)
Net cost (PDP)

Net cost (PDP + ICE)

Net cost (PDP + ICE) – all models
model_profile(explainer_rf, variables = "netcost", N = NULL) |> plot(geom = "profiles")
model_profile(explainer_glmnet, variables = "netcost", N = NULL) |> plot(geom = "profiles")
model_profile(explainer_kknn, variables = "netcost", N = NULL) |> plot(geom = "profiles")Code

Code

Code

Type (PDP)

State (PDP)
Code
# PDP for state
## hard to read
pdp_state_kknn <- model_profile(explainer_kknn, variables = "state", N = NULL)
## manually construct and reorder states
## extract aggregated profiles
pdp_state_kknn$agr_profiles |>
# convert to tibble
as_tibble() |>
mutate(`_x_` = fct_reorder(.f = `_x_`, .x = `_yhat_`)) |>
ggplot(mapping = aes(x = `_yhat_`, y = `_x_`, fill = `_yhat_`)) +
geom_col() +
scale_x_continuous(labels = scales::dollar) +
scale_fill_viridis_c(guide = "none") +
labs(
title = "Partial dependence plot for state",
subtitle = "Created for the k nearest neighbors model",
x = "Average prediction",
y = NULL
) +
theme_minimal(base_size = 9)
Breakdown of random forest
bd1_rf_distr <- predict_parts(
explainer = explainer_rf,
new_observation = cornell,
type = "break_down",
order = NULL,
keep_distributions = TRUE
)
plot(bd1_rf_distr, plot_distributions = TRUE)
plot(bd1_rf_distr)Code

Code

Breakdown of random forest
bd2_rf_distr <- predict_parts(
explainer = explainer_rf,
new_observation = cornell,
type = "break_down",
order = names(cornell),
keep_distributions = TRUE
)
plot(bd2_rf_distr, plot_distributions = TRUE)
plot(bd2_rf_distr)Code

Code

Breakdown of random forest
rsample <- map(1:6, function(i) {
new_order <- sample(1:12)
bd <- predict_parts(explainer_rf, cornell, order = new_order, type = "break_down")
bd$variable <- as.character(bd$variable)
bd$label <- paste("random order no.", i)
plot(bd) +
theme_minimal(base_size = 11) +
theme(legend.position = "none")
})
map(.x = rsample, .f = print)Code






[[1]]
[[2]]
[[3]]
[[4]]
[[5]]
[[6]]
Shapley Additive Explanations (SHAP)
# explain cornell with rf and kknn models
shap_cornell_rf <- predict_parts(
explainer = explainer_rf,
new_observation = cornell,
type = "shap"
)
shap_cornell_kknn <- predict_parts(
explainer = explainer_kknn,
new_observation = cornell,
type = "shap"
)
plot(shap_cornell_rf)
plot(shap_cornell_kknn)Code


Shapley Additive Explanations (SHAP)
# explain cornell with rf model
shap_ith_coll_rf <- predict_parts(
explainer = explainer_rf,
new_observation = ith_coll,
type = "shap"
)
plot(shap_cornell_rf) +
ggtitle("Cornell University")
plot(shap_ith_coll_rf) +
ggtitle("Ithaca College")Code


LIME
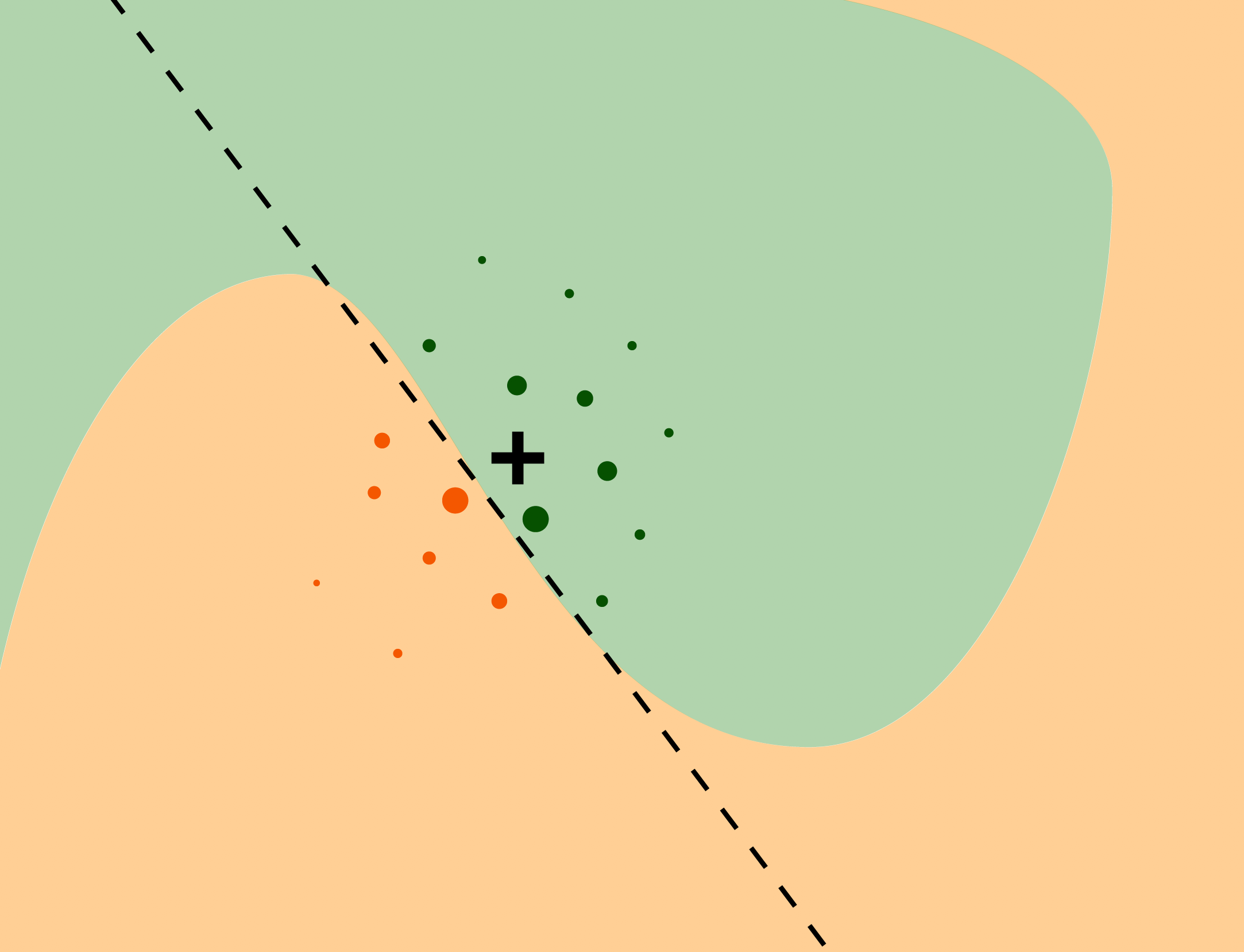
Source: Explanatory Model Analysis
\(10\) nearest neighbors
Code
# prepare the recipe
prepped_rec_kknn <- extract_recipe(kknn_wf)
# write a function to bake the observation
bake_kknn <- function(x) {
bake(
prepped_rec_kknn,
new_data = x
)
}
# create explainer object
lime_explainer_kknn <- lime(
x = scorecard_train,
model = extract_fit_parsnip(kknn_wf),
preprocess = bake_kknn
)
# top 5 features
explanation_kknn <- explain(
x = both,
explainer = lime_explainer_kknn,
n_features = 10
)
plot_features(explanation_kknn) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")
Random forest
Code
# prepare the recipe
prepped_rec_rf <- extract_recipe(rf_wf)
# write a function to bake the observation
bake_rf <- function(x) {
bake(
prepped_rec_rf,
new_data = x
)
}
# create explainer object
lime_explainer_rf <- lime(
x = scorecard_train,
model = extract_fit_parsnip(rf_wf),
preprocess = bake_rf
)
# top 5 features
explanation_rf <- explain(
x = both,
explainer = lime_explainer_rf,
n_features = 10
)
plot_features(explanation_rf) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")
Additional resources
Underlying methods
